Zapper today: 21 scanners across 8 categories, mapped to 8 industry standards.
Updated 8 July 2026: since this post first went up, Zapper has grown from thirteen scanners to 21 across the same eight scanner groups. The tables below reflect the current lineup.
Does shipping code to production leave you waking up in the middle of the night?
It should. Every release is a risk exposure event. AI-assisted development accelerates the rate of exposure without necessarily strengthening the control environment around it. Security hardening sits at the top of that gap - and it doesn't go away just because there's only one of you, or you try your best to ignore it.
I'd been using AI to scan and review my code for security issues. Creating tickets, closing them, and moving on to the next one. It feels like progress. But these non-deterministic tools also give you the theatre of a rigorous process and the appearance of a clean bill of health - what risk advisors call false assurance.
How could I be sure my code had actually been reviewed against what NIST recommends? The frameworks, the tooling categories, the defence-in-depth model? I found freely available OWASP ZAP, ran it against the same codebase I'd just “reviewed”, and found a class of issues the LLM had missed entirely.
That's the lesson I'd suspected was true: defence in depth cannot be delegated to an LLM. No single tool, however capable, covers every angle. Enterprise teams understand this because they have specialisations and independent people running separate tools. Small teams and solo devs don't have that luxury - neither the SME skills, time, nor resources to do it right. That's where Zapper began.
None of this reinvents the wheel. Zapper stands on the work of open-source expert communities: ZAP, Trivy, Garak, Lynis, and others. It makes their tools accessible in one place, and the AI layer is what shapes them into a security pipeline customised to my ways of working.
Why I Built It
The output from security scanners is dense and assumes the reader is already a security specialist. ZAP produces hundreds of findings. Many are duplicates. Many are false positives. Reading and digesting them carefully enough to know which is which takes dedicated specialist time.
So I used an independent AI to review and recommend improvements. The model takes each raw finding, assesses context and false-positive probability, and writes a plain-English explanation. I wanted reports I could actually act on.
That grew into a broader pipeline. Now eight scanner groups feed into a single LLM triage stage, which feeds the reports. That number grows as I think of additional capabilities that blur security review tools with other review tools that reduce my reliance on LLM-only reviews.
Zapper pipeline. One entry point, eight scanner groups covering 21 scanners, one triage stage, unified reports.
Everything Zapper does today:
| Capability | What It Covers |
|---|---|
| Web application scanning (DAST) | Runs OWASP ZAP and Nuclei against a live target, with Schemathesis fuzzing endpoints from an OpenAPI spec and a two-identity check for Broken Object-Level Authorization (BOLA). Triages findings, maps to OWASP Top 10 2025, ASVS 4.0, and OWASP API Security Top 10. |
| Dependency scanning (SCA) | OWASP Dependency-Check plus pip-audit, consolidated, plus Pinned Dependencies checking for unpinned supply-chain versions. CVEs flagged by both databases are marked verified. |
| Container security | Trivy for image CVEs, Hadolint for Dockerfile lint, Docker Bench for CIS Docker Benchmark compliance. |
| Host and infrastructure hardening | Lynis audit for SSH config, file permissions, kernel parameters, and authentication posture. Checkov for infrastructure-as-code misconfiguration across Terraform, Kubernetes, and Dockerfiles. |
| Static analysis (SAST) | Semgrep for security anti-patterns and secrets. OpenGrep for cross-function taint analysis, tracing data flow from source to sink across function boundaries. Betterleaks for secrets left behind in git history even after they are removed from the current tree. |
| Mobile security | MobSF for full APK/IPA static analysis, manifest, binary protections, and certificate pinning. mobsfscan for lightweight iOS and Android source-only scans. |
| LLM endpoint probing | NVIDIA Garak adversarial tests, mapped to OWASP LLM Top 10, NIST AI 600-1, and MITRE ATLAS. Currently in testing. |
| Code quality (Lizard, jscpd) | Lizard scores every function for cyclomatic complexity, lines of code, and a maintainability index across Python, JavaScript, Swift, and 30+ languages. jscpd detects copy-pasted code blocks across the same languages. Together they surface the functions and duplication most in need of attention. |
| AI triage | Each finding analysed by a local LLM for context, likelihood, and false-positive probability with written reasoning. |
| Consensus mode | A second model independently assesses each finding. Disagreements stay flagged as DISPUTED. |
| Workflow reports | HTML, Markdown, and JSON per scanner. Executive summary, Agent Prompt button, copy-as-markdown per finding. |
| Trend tracking | Compare any two scans. See whether things are improving or regressing over time. |
| Web UI and CLI | FastAPI app with a scan wizard and live WebSocket progress, or a single-command CLI for the same pipeline. |
Inside the Architecture
Underneath, Zapper is five layers stacked in a straight line. An entry layer takes the request. An orchestrator runs the work. Eight scanner groups do the probing. A triage pipeline makes sense of what comes back. A reporting layer turns it into something you can act on. Each layer only talks to the one below it, which is what lets me add a new scanner without touching triage, or swap a model without touching the scanners.
The entry layer is a single-command CLI built on Click, the Python library for turning functions into command-line tools, plus a FastAPI web app on port 3200 with a five-step scan wizard and a plain HTML, CSS, and JavaScript front end. Both feed the same orchestrator, which runs each scanner as a background task, streams progress back over a WebSocket, and records every run in a local SQLite database so the history survives between sessions.
The scanners themselves are a deliberate mix. Where a tool ships a fast native binary, Zapper runs it directly: Trivy, Semgrep, pip-audit, and Lynis all run on the host. Where a tool is awkward to install or needs isolation, it runs in Docker: OWASP ZAP, Dependency-Check, MobSF, and Garak. Every container drops all Linux capabilities and runs with no-new-privileges, because a security tool that widens your attack surface is not much of a security tool.
The triage pipeline is where the AI lives. A compressor deduplicates findings and chunks them to fit a model's context window. An analyser routes each chunk through LiteLLM, which puts any model behind a single interface: a small Gemma running locally through MLX at zero marginal cost, or a frontier model in the cloud. A consensus stage then sends contested findings to a second, independent model for a verdict. Routing through LiteLLM is the detail that matters most architecturally: the triage logic never names a specific model, so local and cloud models stay interchangeable.
The reporting layer renders everything through Jinja2 templates with inline SVG charts. Every HTML report is self-contained, with its CSS and JavaScript inlined and no external dependencies, so a report is a single file you can email, archive, or open offline years later.
Drawn out group by group, with the tools and runtimes each stage uses:
Zapper's build, group by group. ZAP keeps its own Scanner, Compressor, Analyser, and Consensus loop; every other scanner - the extended DAST group, SCA, container/host/infra, SAST, mobile, LLM, and code-quality - runs through a shared registry loop that feeds the same Phase 5 report layer. Two model tiers underpin the triage: a local Gemma and a cloud Claude, routed through LiteLLM.
The eight scanner groups, and what each one is looking for:
| Group | Tools | What It Finds |
|---|---|---|
| DAST | OWASP ZAP, Nuclei, API Discovery, BOLA/IDOR, Schemathesis | Live endpoint vulnerabilities: XSS, SQL injection, CSRF, missing headers, insecure cookies (ZAP), known CVE templates (Nuclei), and property-based API fuzzing from an OpenAPI spec (Schemathesis). A two-identity differential check flags Broken Object-Level Authorization. Maps to OWASP Top 10 2025, ASVS 4.0, and OWASP API Security Top 10. |
| SCA | Dependency-Check, pip-audit, Pinned Dependencies | Known CVEs in third-party libraries across two independent databases (findings flagged by both are marked high confidence), plus unpinned dependency versions that weaken supply-chain integrity. |
| Container | Trivy, Hadolint, Docker Bench | Image and filesystem CVEs, Dockerfile issues, Docker daemon configuration against the CIS Docker Benchmark. |
| Host | Lynis, Checkov | OS hardening posture: SSH config, file permissions, kernel parameters, firewall rules, authentication settings (Lynis). Infrastructure-as-code misconfiguration in Terraform, Kubernetes, and Dockerfiles (Checkov). |
| SAST | Semgrep, OpenGrep, Betterleaks | Source code anti-patterns, secrets, and cross-function taint flows tracing user input to dangerous sinks (Semgrep, OpenGrep), plus secrets left behind in git history even after removal from the current tree (Betterleaks). |
| Mobile | MobSF, mobsfscan | APK/IPA manifest security, binary protections, hardcoded secrets, certificate pinning. Covers Swift, ObjC, Java, and Kotlin. |
| LLM Probesin testing | NVIDIA Garak | Adversarial attacks on LLM endpoints: prompt injection, jailbreaks, data leakage, encoding bypass. Maps to OWASP LLM Top 10, NIST AI 600-1, MITRE ATLAS. |
| Code Quality | Lizard, jscpd | Function-level complexity: cyclomatic complexity (CCN), lines of code, token and parameter counts, plus a 0-100 maintainability index (Lizard). Copy-pasted code block detection across the same languages (jscpd). Surfaces refactoring hotspots and duplication. |
Security as a Fitness Function
A DAST scan against a real application produces hundreds of findings. Some are critical. Many are duplicates. Some are false positives generated by the scan itself. Manually triaging all of them, every time, for every project, is not viable.
The point of the pipeline is to turn security into a fitness function - the Building Evolutionary Architectures concept of an automated, objective measure of an architectural characteristic, run continuously rather than audited periodically. Each scanner is one such function. The triage and consensus layer turns raw scanner output into an objective assessment.
Zapper's triage pipeline compresses the output, chunks it for LLM context limits, and sends each finding to a local model for analysis. The model assesses context, likelihood, and false-positive probability, and writes a plain-English explanation of its reasoning.
compress → chunk → analyse → consensus → executive summary
Then consensus mode: a second model independently assesses the same finding. If they agree it's a false positive, it's flagged with high confidence. If they disagree, it stays flagged as DISPUTED with both opinions shown. That transparency matters. The system surfaces uncertainty rather than hiding it.
The result: 200 raw findings become 30 that actually warrant attention.
Cost is managed by design. A small local model (Gemma via MLX) handles triage at zero marginal cost. A frontier model handles consensus verification - in my case Claude Sonnet, but the pattern works with any sufficiently capable model. Token budgets and batching keep costs reasonable, and I'm leaning on subscriptions I already have rather than burning pay-per-token API credit.
LLM Security Probes
If you're running an AI application, the attack surface includes the model itself. Guardrails are good, but red teaming techniques help secure your prompts as well.
Note: Garak integration is currently in active testing. Results and report format are subject to change.
Zapper integrates NVIDIA Garak to run adversarial tests against LLM endpoints. The results map to three taxonomies: OWASP LLM Top 10 v2.0, NIST AI 600-1, and MITRE ATLAS v5.4.0. Every finding gets all three mappings, which matters if you need to speak the language of a specific framework for compliance or reporting.
These mappings should also give you a useful head start on the Australian assurance frameworks now gaining traction - the Voluntary AI Safety Standard, the Australian Government AI Assurance Framework, and ISO 42001 - which share many of the same underlying concepts.
The probe presets I've configured in Zapper:
| Preset | Attack Vector | Good For |
|---|---|---|
| prompt-injection | Direct and indirect injection attacks | Any LLM that accepts user input |
| jailbreak | DAN variants, Grandma exploits, encoding bypass | Models with safety guardrails you need to verify hold |
| data-leakage | Training data extraction attempts | Models fine-tuned on proprietary or sensitive data |
| output-safety | Malware generation, XSS output, harmful content | Models used for code generation or content output |
| hallucination | Package hallucination (supply chain risk) | AI coding assistants that suggest packages |
| content-safety | Toxicity and refusal bypass | Consumer-facing models with moderation requirements |
| quick | Highest-risk categories combined (default) | First run against any new LLM endpoint |
| all | Complete coverage across all categories | Thorough pre-production audit |
Running Garak this way, with Zapper handling orchestration and report generation, means the adversarial test results land in the same visual format as everything else: same severity colours, same executive summary, same Agent Prompt button to copy findings into a remediation session.
“The reports are designed as inputs to action, not archives.”
The Reports as a Workflow Tool
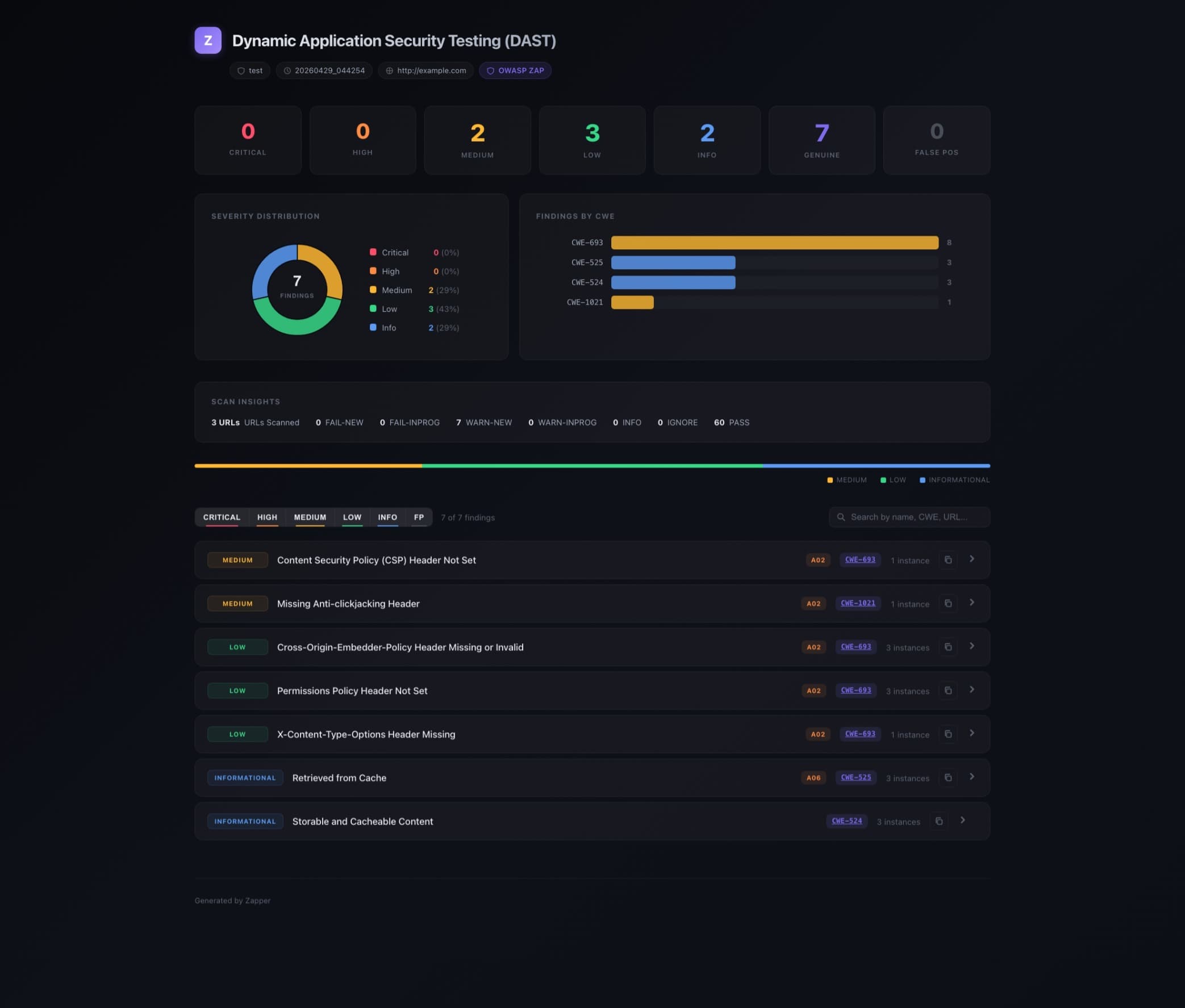
Illustrative only. A Zapper DAST report run against http://example.com, not a real production scan.
Every Zapper report has three things:
Agent Prompt button.
One click generates a structured prompt with the full scan context and findings. Paste it into Claude Code and ask it to address the fixes. The report isn't the end of the process; it's the input to the next step.
Copy-as-markdown per finding.
Each individual finding has its own copy button, separate from exporting the full report. Pull out one specific vulnerability, paste it into a session, deal with it in isolation. Useful when you want to work through findings one at a time without being overwhelmed by the full report.
LLM triage reasoning.
Each finding shows the AI's written justification for its classification. It explains what context made it assess it that way, and what would change the assessment. Transparent and auditable.
Together these make the reports feel different from documentation. They help me understand the security concerns better and educate me at the same time. They're designed as inputs to action, not archives.
Shift-Left Governance, Automated
Step back and the pattern Zapper implements looks structurally identical to an Architecture Review Board:
- Multiple independent reviewers. Each scanner specialises in a different layer - application, dependencies, container, host, LLM - and each finding is then reviewed by two independent AI models. Same separation-of-concerns logic that drives ARBs to bring in security, integration, and data architects separately.
- Transparent dispute. When the two reviewers disagree, the finding stays flagged as DISPUTED with both opinions shown. Mirrors how a well-run governance forum handles split decisions: escalate visibly, don't paper over.
- Evidence-mapped findings. Every result maps to recognised frameworks (OWASP, NIST AI 600-1, MITRE ATLAS, CIS). ADRs do this for architecture decisions; Zapper does it for security findings.
- Action-oriented outputs. Agent Prompt buttons and per-finding markdown drive remediation, not archives. Governance exists to improve delivery, not produce shelfware.
The difference worth naming clearly is that Zapper automates what most enterprises still do manually. Architecture governance today still leans heavily on humans reading deliverables, marking them up, and writing reasoned opinions. That model is bounded by reviewer capacity - which is why ARBs become bottlenecks the moment delivery scales. Zapper applies the same governance philosophy but pushes it down to where the code lives, runs it on every change, and produces evidence the Three Lines of Defence can all consume - first-line developers acting on Agent Prompt remediation, second-line control functions reading framework-mapped findings, third-line audit tracing decisions back through transparent triage reasoning.
I wrote about lightweight, risk-based governance earlier in Dare to Shift Left on Architecture Governance. Zapper is what happens when you take that philosophy and ask: what if the reviewers were also AI?
What I Learned Building It
Touching this many security frameworks teaches you the landscape by necessity. You end up gaining a better appreciation of OWASP Top 10 2025, ASVS 4.0, CIS Docker Benchmarks, NIST AI 600-1, and MITRE ATLAS not because you studied them but because you had to wire them into report templates and taxonomy mappings.
The bigger lesson is to start from what already exists. The hard problems in security scanning - parsing CVE feeds, fingerprinting CWEs, running adversarial probes - have been solved by people who specialise in them. The leverage is in the integration, not the invention.
And LLMs have changed the economics of building for yourself. A pipeline like this would have been a product team's roadmap a few years ago. With local models doing the routine work and a frontier model doing the verification, one developer can build something shaped to their context rather than buying a SaaS product designed for someone else's.
There was a quieter lesson about interfaces. The CLI turned out to be more than a convenience: a coding agent can call it directly while working on your code, with no web front end in the loop. Having both the CLI and the web UI meant I could pick whichever suited where a tool was in its maturity - the wizard for exploring a new scanner, a single command once I knew exactly what I wanted. And because every report also exports as markdown, I could feed one specific finding straight back to a coding agent and keep the next change tight and focused, rather than gesturing at a whole dashboard.
jscpd taught me the lesson I least expected. The amount of copy-pasted duplication it found across the codebase, including in the .css files, was well beyond what I'd expected. I'd assumed the coding-agent instructions I'd already written down would have caught that on their own. They hadn't, and that gap is the point: a written instruction is guidance a model can weigh against everything else competing for its attention in a given context; a scanner is a check that runs whether or not the model remembered. It's a small, concrete reminder of a limit in probabilistic code generation that no amount of upfront instruction fully closes.
Where Next
Stepping back from security, the same pattern fits the rest of the DevSecOps lifecycle. Security is one quality lens. Code complexity is another. So are test coverage, mutation testing (introducing small bugs into your code to test the quality of your testing), linting, documentation, and the size of a change. Each already has mature open-source tooling behind it. The pipeline that triages ZAP findings is the same shape that could gate any of them.
The thing I most want to keep in check is the quality of my own AI-generated code. Left to its own devices, an LLM cheerfully produces volume: more lines, more indirection, more plausible-looking abstractions than the problem needs. Lizard scores every function for cyclomatic complexity and a maintainability index, and jscpd flags copy-pasted duplication across the same languages, including .css files. I've folded both into the same triage-and-report flow, and “is it secure?” becomes one question among several: is it secure, is it simple, is it tested, is it readable, is it duplicated, and is it maintainable?
Guiding generation, not just catching it
Everything above catches problems after the code is written. The area I actually want to grow into next is upstream of that: shaping what gets generated in the first place. Every coding agent works from some version of a skills.md or CLAUDE.md file, standing instructions it consults before writing a line. Mine are personal, built up from my own preferences and past mistakes.
The fix is the same one Zapper is already built on: source that layer from an authoritative, community-maintained catalogue instead of reinventing it alone. OWASP's secure-agent-playbook is a good example - seventeen security skills distributed as Claude Code plugins, each grounded in a named standard (ASVS, the OWASP Top 10, MASVS, FIASSE) rather than personal notes. Most of them review code after it's written, the same job Zapper already does. A couple point the other way - securability-engineering and prd-securability-enhancement guide code and specs toward ASVS-covered, FIASSE-aligned patterns before anything gets scanned - and the project credits a companion effort, the OWASP Agent Skills Project, built specifically so that, in their words, “they guide code generation, we find vulnerabilities in existing code.”
That is the shape I want to grow into: the same OWASP references already anchoring Zapper's reports feeding the coding agent's instructions on the way in, not only the scanner's findings on the way out. It is not a guarantee - a skill file, however authoritative, is still guidance a probabilistic model can weigh against everything else in its context, exactly the gap jscpd exposed. That is why the scanning stays. Authoritative skills at generation time and independent scanning after it are the same defence-in-depth logic, applied to two different moments in the same pipeline.
Defence in depth is not only a lesson for security. It turns out to be the lesson for keeping AI-assisted code honest, too.
Oh, and it helps you sleep a tiny bit better at night.
If you're thinking about AI security governance at enterprise scale, I'd be interested to talk.
Vinod Ralh is an Enterprise Architect specialising in AI governance and responsible AI delivery.